
Google file system
Paper Review: Google File System
Overview
In a given cluster, there can be thousands of comodity clusters. Think of this as a filesystem distributed over several comodity clusters. The word comodity has a significance here. The aim of Google here was to use relatively cheaper and less reliable hardware rather than expensive high endurance, high performance hardware.
Design Considerations
-
Comodity hardware: Instead of buying expensive hardware, buy comodity hardware that is cheaper. Use software to scale out. Implement the software to handle disk, network, server faults. Additionally, also consider OS bugs and human error.
-
Optimized to store and read learge files. This means even the smallest file is bigger than your typical file.
-
Optimized for read+append only, no random writes and only sequential reads.
-
Chunk size of 64MB to reduce metadata.
These considerations were for the search engine application, where the aim of google was to create a large document and implement reverse indexing.
Working model
-
Chunks Single file is not stored on a single server. The file is sub-divided into chunks. Each chunk is of 64MB, spread across multiple machines. Each machine is a chunk server. Each chunk has atleast three replicas across three different servers.
-
GFS master a. Stores metadata about the cluster. b. Contains file names, how many chunks per file, ID of each chunk and which server the chunks reside. c. Access control about clients
- How reads are done:
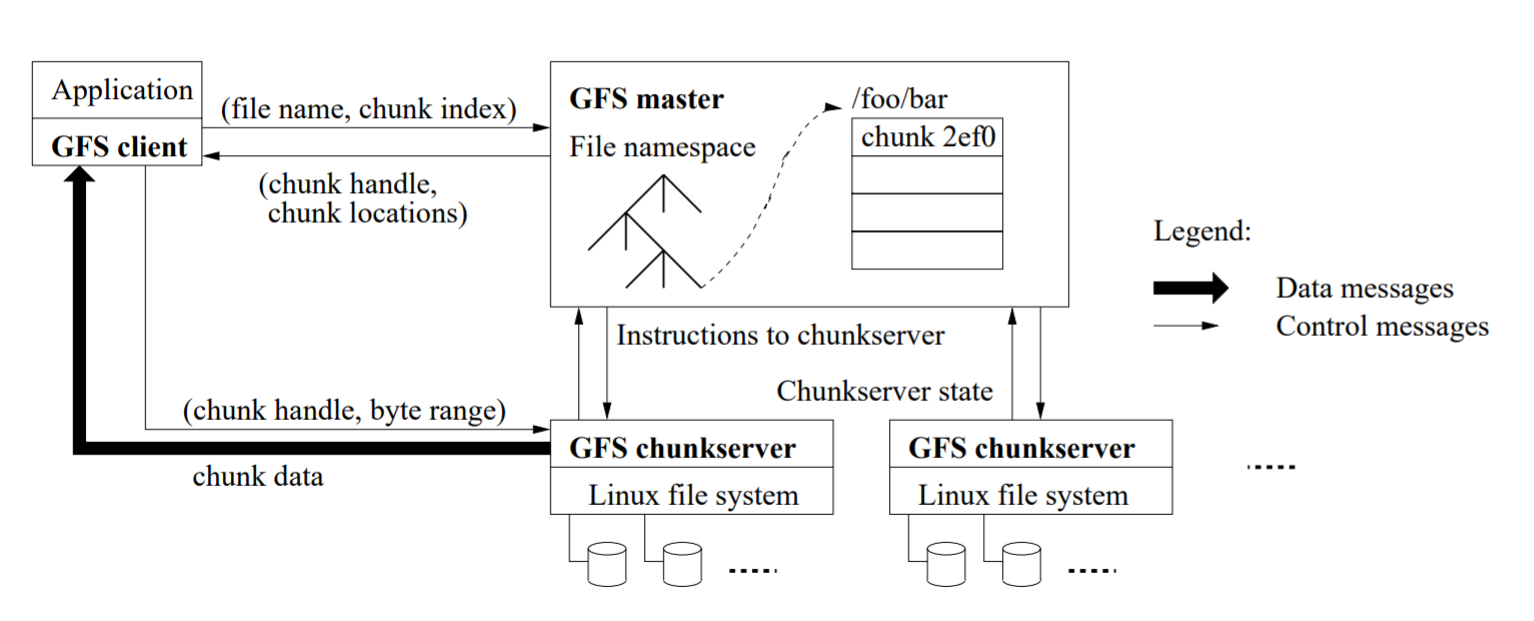
- Client asks GFS master for file, GFS master returns the IP address of the nearest chunk server, chunk server and the client can communicate directly.
- How writes are done:
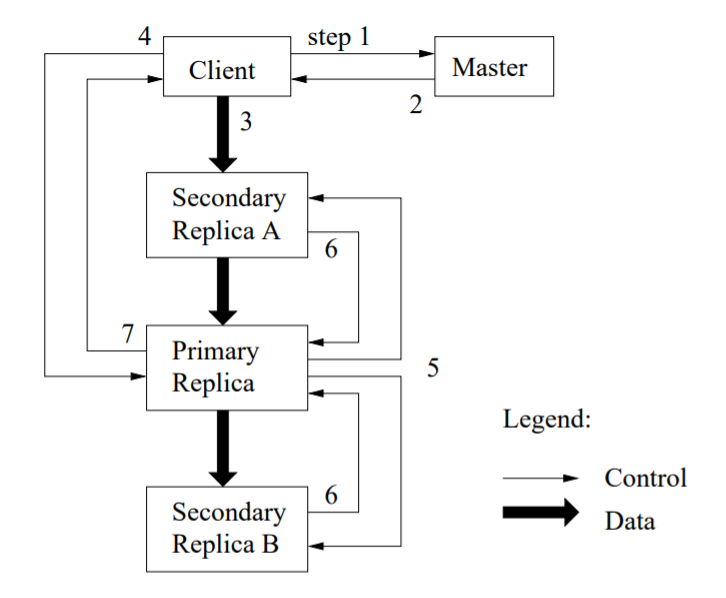
- Ask the master for chunk servers which contain chunks. Master returns list of chunk servers which have more free space.
- The client chooses the closest server from the list, and transfers all data to that replica.
- This replica transfers the data to all other replicas.
- Each of the chunk server now has the data, but writes are still not commited.
- Client sends request to primary replica to commit.
- Replica ensures writes done across all replicas, only then sends ack to keep the writes atomic.
Some of the advantages of writes are that data and control flow is seperated, and the entire mechanism very effectively utilizes the bandwidth.
-
Hearbeat messages are sent to chunk servers to ensure they are alive. If a server dies, use the remaining replicas to create a third instance to ensure n chunks.
-
Operations Log:
- Append only log stores each file operation with user details.
- Directly written to disk and replicated only then acknowledgement sent.
- If master crashes, the log can be used.
- To keep size of log small, it is checkpointed regularly.
Practically, there is a shadow master, although it may lag slightly as compared to the master.
Some more implementation details:
- Chunk servers perform checksums to avoid file corruption.
- checksum failures reported to master
- Master can rebalance the chunks to manage load on chunk servers
