Scene classification using Scene Parsing, NLP and Neural Networks
Understanding the final task and overview of methodology
The goal is to build a model that takes in a list of objects that are present in a scene, and predict the type of scene. For example if you see table chair, plates, knifes and fork it is probably a restraunt. But if we remove table and chair and add in a microwave and a gas stove our model should tell us that this is a kitchen.
The birds eye view of the solution:
- If we have a dataset containing scenes classified into scene categories,
- And if we can obtain objects present in those scenes,
- We could use supervised Machine Learning and Information retrival techniques to get a model!
Feature Engineering
Now, how do we address each of the points mentioned above:
- Use places365 dataset, where we have exactly what we mentioned in point 1
- Unified parsing is again an approach developed at CSAIL which gives an elegant solution to 2 (although some assumptions read below)
- TF-IDF, Word Vectorization(Available in the open-source) and Neural Nets (possibly Adaboost and other ML algorithms also) could be used
Steps 1 and 2 can be used to obtain a dataset such that we have this kind of representation, this can be used to run a variety of machine learning algorithms.
This can be called a type of feature engineering that we did.
-------------------------------------------
| imagename | objects_present | scenetype |
-------------------------------------------
| | | |
-------------------------------------------
| | | |
-------------------------------------------
| | | |
. . . .
. . . .
. . . .
. . . .
Scene parsing to obtain objects present in an image (image of the scene)
Review of literature took me to a project titled Unified Perceptual Parsing for Scene Understanding, which was presented as https://arxiv.org/abs/1807.10221. There are a few pre-trained models provided by authors. Scene parsing gives us objects present in the scene out of the 335 objects that it has been trained for.
Data engineering
As discussed in the first section, we will be using the places365 dataset. In the project, due to the hardware constrainints, I chose only 10 scene classes, with 5000 images for each class. For each of the 5000 images for 10 classes, I will be performing unified parsing. Looking closely at the test.py script in the scene parsing code and profiling it, one forward pass, i.e execution for one image takes around 1 minute on a Nvida P100. This would make obtaining results for 5000*10 images impractical.
Some of the optimizations done were:
- Nvidia T4 is more suitable for inference workloads, use that instead.
- Load the neural network model and weights only once.
- Remove material prediction, parts prediction from the workload.
- Use multithreading for some of the tasks like writing data
By doing these I was able to bring the time down to 2-3 seconds. Dramatic reduction that makes dataset generation possible in a few days.
A quick look at the various approaches taken
IMHO, looking at the matrices is the best way to understand what the f*** is going on internally. So I have three approaches here, as also discussed in the paper, you can find at the end of this page. Also before we move forward, when I say image, it means a unique name given to the image, i.e imagename, since we have parsed the image into a list of objects, all we need to remember is the image name and the scene label corresponding to the image.
The three approaches are:
- TF-IDF approach
- TF-IDF with NLP approach
- Neural Network approach
This is the most meaty section, and really cool. Learning about TF-IDF and some introduction to NLP was quite interesting.
- TF-IDF
TF-IDF is an elegant approach. And I felt like I’ve been living under a rock when I first discovered this in this project. My project partner came up with the idea of using this approach. Let us assume we have several documents, which contain thousands of words. In terms of a document, (TF) term frequency tells us how frequently a given word comes up in the document. In our case each scene class (10 classes) is our document, and object is the word. So we want to determine how frequently an object is found in a scene type.
TF gives rise to a problem that there could be words that are not very frequent, yet important to distinguish documents and words that are so frequent, that they don’t really help us in distinguishing a document from another because they are almost universal across the document. Imagine articles “a”, “an”, “the”.
In our case, imagine objects like say floor, which will be present in many scene categories, so we should give it less weight while trying to determine a scene.
IDF takes care of it, it is the total number of times an object appears in each of the scenes categories. The image explains this.
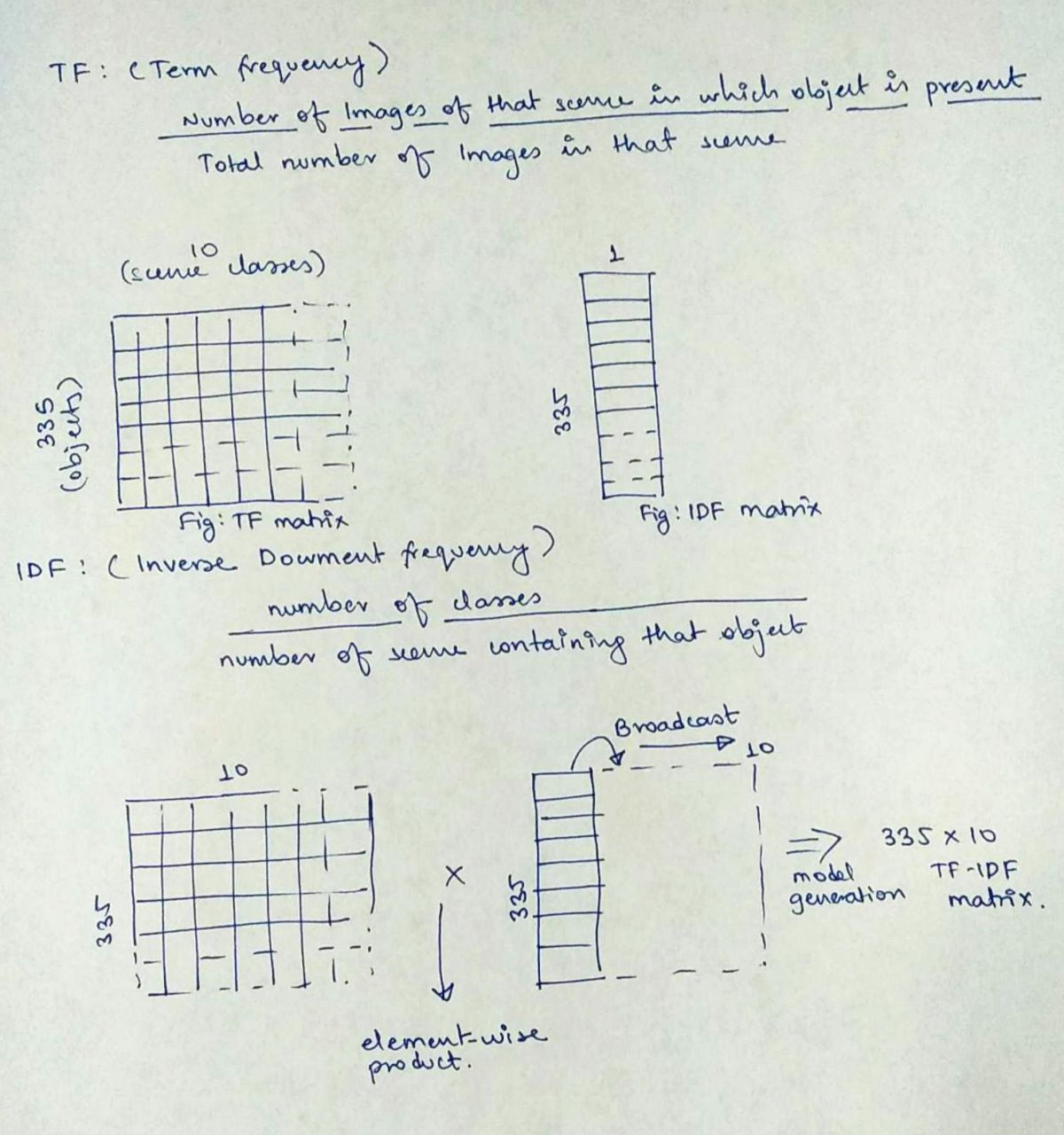
Since we have 335 objects and 10 scene categories, we calculate TF for each scene by iterating over 5000 images in training set. This yields a 335 x 10 matrix. IDF on the other hand is calculated for each object across all categories. Hence 335 x 1 sized matrix. We broadcast it into a 335 x 10 and perform element-wise multiplication to obtain the TF-IDF matrix.
- TF-IDF with NLP
Aren’t the words “airplane” and “runway” related by the underlying context of air travel? Is there a way this context information could be used to add contextual information between objects and scenes? Word vectors in form of Glove and Word2Vec provide a readymade solution to this. We look to incorporate that and then add weights from TF-IDF to further increase its accuraccy. Glove with the twitter300 model that I used resulted in something that is explained below.
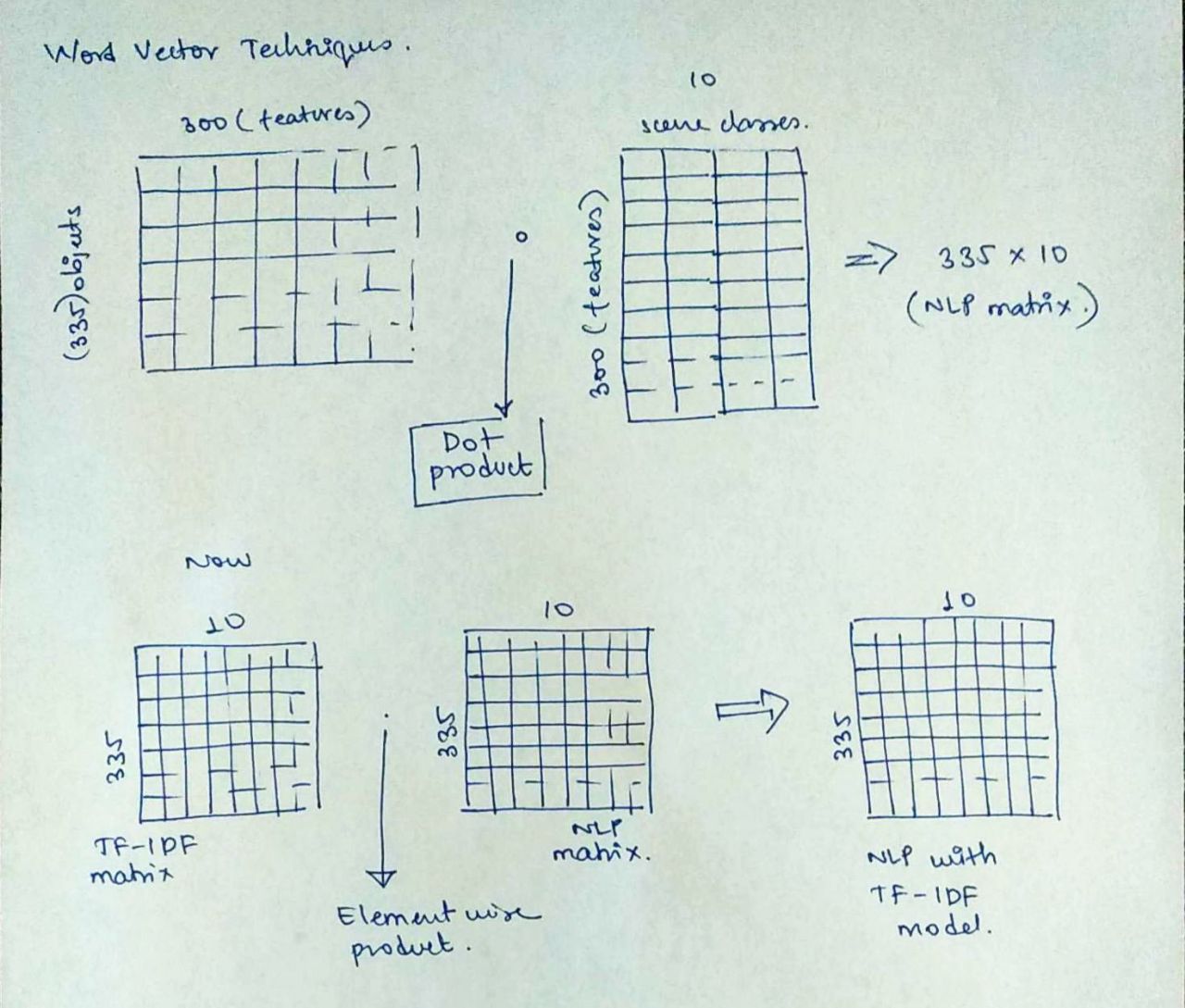
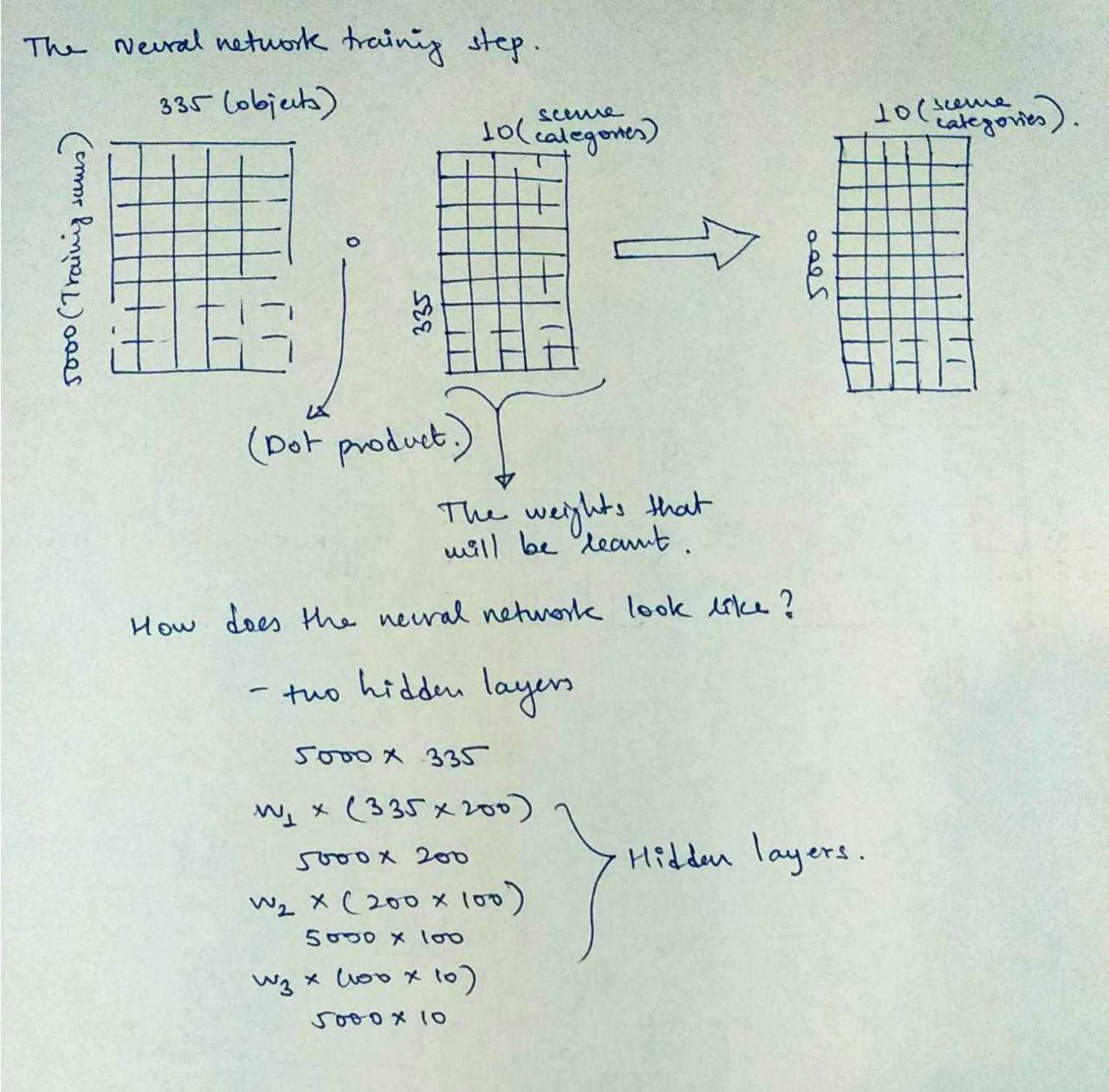
- Neural Network approach
The NN approach was quite simple as I didnot have to use any convolutions here, and a two-layers network with some non-linearity and Relu() did the job for me.
Testing and Results
A testing dataset was created similar to the way how training dataset was created but only 500 images per scene category.
Surprisingly, NLP along with TF-IDF, which seems so elegant was defeated by Neural Network. This is really a proof of the power that neural networks hold. In a way, backpropogation learns about what is relevant to understand a scene, and possibly, we can never be fully sure what it learnt!
Read more in this paper here!